![]()
![]()
|
Xerox Palo Alto Research Center
3333 Coyote Hill Road
Palo Alto, CA 94304, USA
email: {pirolli, rao}@parc.xerox.com, pitkow@cc.gatech.edu
*authors are ordered alphabetically
We suggest that the ecological approach of Information Foraging Theory [12] motivates the use of techniques for automatic categorization and a particular kind of associative retrieval of WWW pages involving spreading activation [4]. Categorization techniques are used to identify and rank particular kinds of WWW pages, such as "organization home pages" or "index pages." Associative retrieval techniques identify and rank pages predicted to be related and relevant to currently viewed pages. Both techniques work on the basis of a variety of features of WWW pages, including the text content, usage patterns, inter-page hypertext link topology, and meta-document data such as file size and file name. In combination, these techniques may be used in support of novel information visualization techniques, such as the WebBook [6], to form and present larger aggregates of related WWW pages. We will argue that these techniques can be used to optimize user information-seeking and sensemaking.
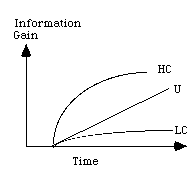
Imagine that a user coming upon a web locality is analogous to a predator such as a lion coming upon an open plain with a teeming array of potential prey species: The optimality of the diet or pursuit sequence chosen by the predator (or user) will depend on their ability to rapidly categorize the prey types (WWW page types), assess their prevalences on the plain (web locality), assess their profitabilities (amount of return over cost of pursuit), and decide which categories to pursue and which to ignore. The optimization can be further improved to the extent that the category members can be ranked, so that good examples of a good category could be pursued first. Figure 1 provides a graphical illustration of the improvements provided by categorization and ranking (see Pirolli and Card [12] for detailed technical discussion).
The WWW can be viewed as an external memory and a user-forager would be aided by retrieval mechanisms that predicted and returned the most likely needed WWW pages, given that the user is attending to some given page(s). We will use a kind of spreading activation mechanism [4] to predict the needed, relevant information, computed using past usage patterns, degree of shared content, and WWW hyperlink structure.
Visualizations can be applied to the Web by treating the pages of the Web as objects with properties. Mukerjea [11] has applied a number of visualizations to the Web. Each of these provides an overview of a Web locality in terms of some simple property of the pages. For example, a Cone Tree shows connectivity structure between pages and a Perspective Wall shows time-indexed accesses of the pages. Thus, these visualizations are based on one or a few characteristics of the pages.
As argued above, our approach to extracting structure from the Web using categorization and spreading activation, can be used to form higher level abstractions that reduce the complexity and increase the richness of an overview. We have developed methods for annotating pages with their functional types and relevancy/importance assessments as well as aggregating the Web into collections which can be treated as collections. These collections could be visualized as WebBooks in the WebForager [6].
We have gathered information for several Web localities, but in this paper, we focus on the pages served by the Xerox WWW server. Our goal was to analyze this data and to design algorithms for various extractors which would annotate and aggregate WWW pages at this Web locality. In particular, we have designed methods for classifying nodes into a number of functional categories, and spreading activation based on selecting one or more source nodes (WWW pages) and dimensions of interest, and aggregating nodes into higher level collections.
Categorization techniques typically attempt to assign individual elements (e.g., WWW pages) into categories based on the features they exhibit. Based on category membership, we may quickly predict the functionality of an element. For instance, in the everyday world, identifying something as a "chair" enables the quick prediction that an object can be sat on. Our techniques rely on particular features we can extract about WWW pages at a Web locality.
One may conceive of a Web locality as a complex abstract space in which WWW pages of different functional categories or types are arranged. These functional categories might be defined by a user's specific set of interests, or the categories might be extracted from the collection itself through inductive technologies [13]. An example category might be organizational home page. Typical members of the category would describe an organization and have links to many other Web pages, providing relevant information about the organization, its divisions or departments, summaries of its purpose, and so on.
We specified a set of functional categories for this study that correspond to the various roles that Web pages typically play. Each functional category was defined in a manner that has a graded membership, with some pages being more typical of a category than others, and Web pages may belong to many categories. Specifically, we defined the following types of Web pages for our study:
In summary, given this conception of a Web locality, we use three component processes to identify and extract Web structure. First is the categorization of Web pages into types and the users' selection of pages according to their degree of category membership in different types. Second is the spread of activation from the identified sources through some combination of the link connectivity, text similarity, and usage spaces. Third is the selection and aggregation of Web pages based on their pattern of relevancy as measured by activation.
Table 1. Node type definitions and results.
Node Type Size Number Number Depth Similari Freq. Entry Precisio
Inlinks Outlinks of ty to Point n
Children Children
Index - + 0.67
(outlinks/si
ze)
Source Index - + + 0.53
(outlinks/si
ze)
Reference + - - - 0.64
Destination + - - - - 0.53
Reference
Head + + + + 0.70
Org. Home Page + + + + 0.30
Personal Home > 1 k & < 3 - - 0.51
Page k
Content + - - 0.99
The algorithm we implemented to determine user's paths, a.k.a. "the whittler", utilized the Web locality's topology along with several heuristics. The topology was consulted to determine legitimate traversals while the heuristics were used to disambiguate user paths when multiple users from the same machine name were suspected. The latter scenario relies upon a least recently used bin packing strategy and session length time-outs as determined empirically from end-user navigation patterns [7]. Essentially, new paths were created for a machine name when the time between the last request and the current request was greater than the session boundary limit, i.e., the session timed out. New paths were also created when the requested page was not connected to the last page in the currently maintained path. These tests were performed on all paths being maintained for that machine name, with the ordering of tests being the paths least recently extended. This produced a set of paths requested by each machine and the times for each request. From this, a vector that contained each node's frequency of requests and a matrix containing the number of traversals from one page to another were computed using software that identified the frequency of k-substrings for any n-string [14]. These are referred to hereafter as the frequency vectors and the path matrix respectively.
Additionally, the difference between the total number of requests for a page and the sum of the paths to the page was computed. Intuitively this generates a set of entry point candidates. These are the WWW pages at a Web locality that seem to be the starting points for many users. Entry points are defined as the set of pages that are pointed to by sources outside the locality, e.g., an organization's home page, a popular news article, etc. Table 2 shows the results of this analysis. The Xerox Home page and the 1995 Xerox Fact Book are the top pages identified are among the pages most visited by users, as might be expected of people seeking information about Xerox. Also among the top WWW pages are Xerox PARC's Digital Library Home Page, PARC's Map Viewer, the Bookwise Home Page, all of which have received substantial outside press or awards that would draw the attention of users. Entry points might provide useful insight to Web designers based on actual use, which may differ from their intended use on a Web locality. Entry points also may be used in providing a set of nodes from which to spread activation.
Table 2. The most popular starting points
% Visits Number Pages Outside Visits 99.96 2662 /95FactBook/Title.html 96.18 12377 /PARC/docs/mapviewer-legend-world.html 99.58 16004 /Products/XIS/BookWise.html 99.99 19130 /PARC/dlbx/library.html 94.29 24107 / (the default Xerox Home Page)
Given the above properties and shapes of the distributions, linear separable categories were assumed. This enabled categories to be identified by solving a set of linear equations of the form:
ci = w1 v1 + w2 v2 + ... + wn vn (1)
for all nodes i in Xerox Web space, where the vj are the measured features of each Web page, and the wj are weights. In what follows, these weights were set a priori by us to be either -1, 0, or +1. Future works may investigate classification algorithms for optimizing the setting of these weights, for instance, by using Linear Discriminant Analysis, or more sophisticated machine learning techniques.
Table 1 shows the weights used to order Web pages for each of the categories. For example, we hypothesized that Content Nodes would have few inlinks and few outlinks, but have relatively larger file sizes. The equation used to determine this category of nodes has a positive weight, +1 on the size feature, and negative weight, -1, on the inlink and outlink features. For Head Nodes, being the first pages of a collection of documents with like content, we expected such pages to have high text similarity between itself and its children, would have a high average depth of its children, and that it would be more likely to be an entry point based upon actual user navigation patterns.
As one would expect due the large number of content nodes in a Web locality, the precision at which content nodes can be identified was quite high (precision = .99). Equally encouraging was the identification of Head and Index Nodes (precisions of .70 and .67 respectively). Table 3 shows the list of top five Head Nodes. Not surprisingly, the lowest precision in Table 1 was associated with the correct identification of Organizational Home Pages, of which there are only about ten such pages at the Xerox Web locality.
Table 3. The top 5 head nodes.
Titles of Page
Digital Tradition Keywords
RXRC Cambridge Technical Report Series
Ken Fishkin's Public Home Page
Why are Black Boxes so Hard to Reuse?
Xerox Corporation 1994 Form 10-K
Suppose a user is interested in a set of one or more Web pages and wants to find related pages to form a small Web aggregate, such as a WebBook [6]. We assume that the identification of such "interesting seed sets" of Web pages could also be automatically determined based on functional category using methods described above.
Each entry in the ith column and jth row of a matrix represents the strength of connection between page i and page j (or similarly, the amount of potential activation flow or capacity). The meaning of these entries varies depending on the type of network through which activation is being spread:
A(t) = C + M A(t - 1), (2)
where M is a matrix that determines the flow and decay of activation among nodes. It is specified by
M = (1 - [[gamma]]) I + [[alpha]] R, (3)
where [[gamma]] < 1 is a parameter determining the relaxation of node activity back to zero when it receives no additional activation input, and [[alpha]] is a parameter denoting the amount of activation spread from a node to its neighbors. I is the identity matrix.
Huberman and Hogg showed that the characteristic dynamical behavior of spreading activation depends on the relation among [[gamma]], [[alpha]], and the mean number of arcs per node, u. In the general case, there is a phase transition when [[alpha]] = [[gamma]]. When [[alpha]]/[[gamma]] is small, the total activation in the net rapidly rises to an asymptotic pattern and is localized in the network. When [[alpha]] > [[gamma]], there is another phase transition at u= 1. With [[alpha]] > [[gamma]], when the network contains sparsely connected nodes with u < 1, the total activation rises indefinitely but the pattern remains localized. Our usage path graph structures are such sparse networks. With [[alpha]] > [[gamma]], with richly connected nodes with u > 1, the total activation rises indefinitely and all parts of the network affect all others, so that inputs of activation at any node tend to create the same pattern of activation. Our text similarity graphs are richly connected graphs. Given this characterization of the phase space of spreading activation regimes, we chose parameters such that [[alpha]]/[[gamma]] << 1 to identify Web structure aggregates.
In Table 4, it is evident that a user who is focused on the Xerox home page is predicted to then shift their attention (by traversing web links) to WWW pages describe mainly xerox products, businesses, and financial reports. From this, we might infer that users interested in the Xerox home page are also interested in what Xerox sells or how they are doing financially.
Activation Source Network Most Active Web Pages Found
(No. found)
Xerox Home Page Usage paths Xerox product descriptions (10)
Financial reports (6)
Business Division home pages (5)
General info (2)
Search form (1)
Highest rated Text Group project overviews (5)
member of Personal similarity Other people hotlists (4)
Home Page category Company info (4)
Personal interests (4)
Other similar people (3)
Informal groups (1)
Workshop attendee list (1)
Wildlife award report (1)
Someone else's talk (1)
Consider another situation in which we are interested in the Web pages having the highest text similarity to the most typical person page in a Web locality. In other words, we might be interested in understanding something about what a typical person publishing in a Web locality says about themselves. In this case, the most typical person page is identified as in Table 1, the corresponding C element set to positive activation input (zeros elsewhere), and R is set to the text similarity matrix. Iteration of this spread of activation for N = 10 time steps selects the collection described in Table 4. By reading the group project overviews, the home pages of related people, personal interest pages, and formal and informal groups to which the person belongs, we should get some sense of what people are like in the organization.
Applying their first algorithm to the graph structure of the Xerox Web produces 10 web groups with at least 10 nodes. In addition, we tried an algorithm which iteratively removes articulation points until all groups are below 25 nodes in size or contain no articulation points. We didn't remove indices or references during iteration. This leads to 9 clusters (again of at least 10 nodes. The two algorithm produced 8 web groups in common, though often not including the same nodes. In addition, the simplified algorithm produced one extra web group, while the 2 extras web groups produced by the Botafoga algorithm were caused by splitting a web group and by including a spurious web group.
These algorithms were quite effective at pulling out highly-connected book structures. For example, one 13 node book was a TOC with 12 nodes for sections which pointed back and forth. However such structures are highly-authored sections of the web and cluster together in a number of ways. For example, there was a high correlation between the URLs of the nodes within these web groups. Most of the nodes typically shared a prefix of two or three pathname parts, though web groups that were less book-like tended to also bring in a few nodes from other locations on the server. More systematic comparison of pure topology-based methods and those based on one or more of the sources outlined here is an open area for further work.
2. Anderson, J.R., Rules of the mind. Lawrence Erlbaum Associates, Hillsdale, NJ, 1993.
3. Anderson, J.R. and R. Milson, Human memory: An adaptive perspective. Psychological Review, 96 (1989). 703-719.
4. Anderson, J.R. and P.L. Pirolli, Spread of activation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10 (1984). 791-798.
5. Botafogo, R.A. and B. Schneiderman. Indentifying aggregates in hypertext structures. in Third ACM Conference on Hypertext. (1991, San Antonio, TX). ACM. pp. 63-74.
6. Card, S.K., G.G. Robertson, and W.M. York. The WebBook and the Web Forager: An Information Workspace for the World-Wide Web. in Conference on Human Factors in Computing Systems, CHI-96. (1996) ACM.
7. Catledge, L. and J. Pitkow, Characterizing browsing strategies in the World-Wide Web. Computer Networks and ISDN Systems, 27 (1995).
8. Cutting, D.R., J.O. Pedersen, and P.-K. Halvorsen. An Object-Oriented Architecture for Text Retrieval. in RIAO '91 Intelligent Text and Image Handling. (1991, Barcelona, Spain). pp. 285-298.
9. Dawkins, R., The selfish gene. Oxford University Press, Oxford, 1976.
10. Huberman, B.A. and T. Hogg, Phase transitions in artificial intelligence systems. Artificial Intelligences, 33 (1987). 155-171.
11. Mukherjea,S., J.D.Foley, and S.Hudson. Visualizing complex hypermedia networks through multiple hierarchical views. in Human Factors in Computing Systems CHI-95.(1995, Denver, CO). ACM. pp. 331-337.
12. Pirolli, P. and S. Card. Information foraging in information access environments. in Conference on Human Factors in Computing Systems, CHI-95. (1995, Association for Computing Machinery. pp.
13. Pirolli, P., P. Schank, M. Hearst, and C. Diehl. Scatter/Gather browsing communicates the topic structure of a very large text collection. in Conference on Human Factors in Computing Systems, CHI-96. (1996) Association for Computing Machinery.
14. Pitkow, J. and C. Kehoe. Results from the Third WWW User Survey. in The World Wide Web Journal, 1 (1995).
15. Robertson, G.G., S.K. Card, and J.D. Mackinlay, Information visualization using 3D interactive animation. Communications of the ACM, 36 (1993). 57-71.
16. Smith,E.A.and B.Winterhalder,ed.Evolutionary ecology and human behavior. de Gruyter, New York, 1992.
17. Stephens, D.W. and J.R. Krebs, Foraging theory. Princeton University Press, Princeton, NJ, 1986.
18. Taubes, G., Indexing the internet. Science, 8 (1995). 1354-1356.
19. vanRijsbergen, C.J., Information retrieval. Butterworth & Co., Boston, MA, 1979.